
独家对话姚顺宇:请允许我小疯一下
独家对话姚顺宇:请允许我小疯一下他人生最大的一次跨步是博士毕业,毅然决然离开深造9年的物理,来到崭新的AI行业。过去两年,他先后在Anthropic和Google DeepMind出任研究科学家,参与了Claude 3.7、4.5、Gemini 3等关键模型的开发过程。
来自主题: AI资讯
13124 点击 2026-05-11 12:03
 搜索
搜索
他人生最大的一次跨步是博士毕业,毅然决然离开深造9年的物理,来到崭新的AI行业。过去两年,他先后在Anthropic和Google DeepMind出任研究科学家,参与了Claude 3.7、4.5、Gemini 3等关键模型的开发过程。

OpenAI的最新研究揭示了一个反直觉的真相:越强大的推理模型,越管不住自己的「脑子」。在CoT-Control套件测试的13款前沿模型中,DeepSeek R1控制自身思维链的成功率仅为0.1%,Claude Sonnet 4.5也只有2.7%。
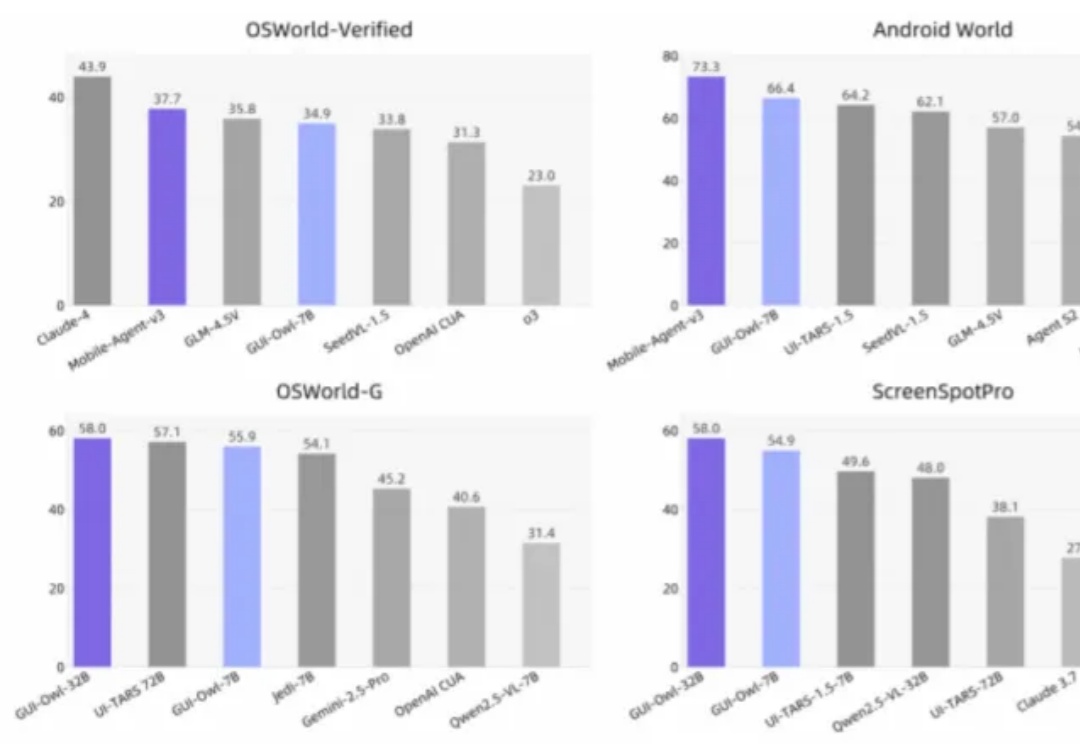
覆盖桌面、移动和 Web,7B 模型超越同类开源选手,32B 模型挑战 GPT-4o 与 Claude 3.7,通义实验室全新 Mobile-Agent-v3 现已开源。

最顶尖的AI模型,做起奥数题来已经和人类相当,那做物理题水平如何呢?港大等机构的研究发现:即使GPT-4o、Claude 3.7 Sonnet这样的最强模型,做物理题也翻车了,准确率直接被人类专家碾压!
自 Anthropic 推出 Claude Computer Use,打响电脑智能体(Computer Use Agent)的第一枪后,OpenAI 也相继推出 Operator,用强化学习(RL)算法把电脑智能体的能力推向新高,引发全球范围广泛关注。
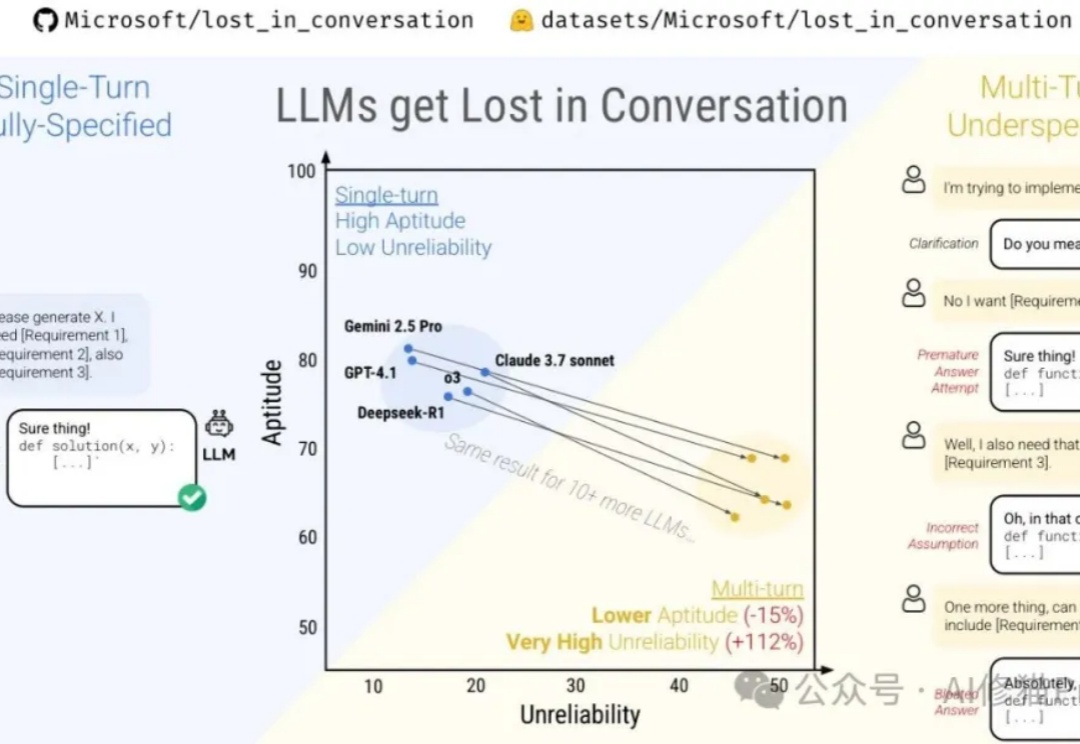
微软最近与Salesforce Research联合发布了一篇名为《Lost in Conversation》的研究,说当前最先进的LLM在多轮对话中表现会大幅下降,平均降幅高达39%。这一现象被称为对话中的"迷失"。文章分析了各大模型(包括Claude 3.7-Sonnet、Deepseek-R1等)在多轮对话中的表现差异,还解析了模型"迷失"的根本原因及有效缓解策略。

用1/8成本比肩Claude 3.7,刚刚,“欧洲OpenAI”Mistral AI发布多模态新模型。

谷歌Gemini 2.5 Pro(I/O版)横空出世,强势登顶LMAreana,斩获文本、视觉、编码三连冠,甚至编程能力全面碾压Claude 3.7,地表最强编码模型诞生。

自 OpenAI 发布 chatgpt 以来,业内除了技术公司、媒体公司比较关注其进展以外,还有一个行业比较关注,那就是战略咨询行业。尤其是最近 GPT-4o、Claude 3.7 Sonnet 为代表的最新大模型在数据分析、内容生成、编码和复杂推理方面展现出强大能力,与战略咨询工作的核心环节高度相关 。
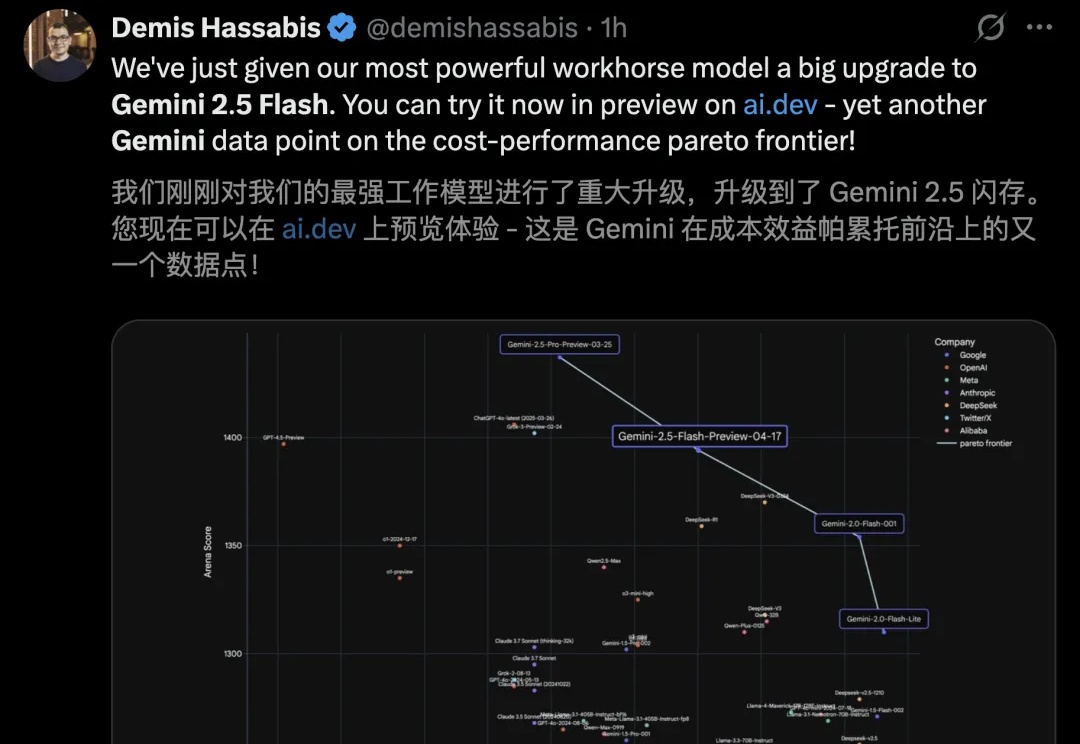
谷歌发布首款混合推理模型Gemini 2.5 Flash,引入了革命性「思考预算」,可灵活控制推理深度,性能一举击败Claude 3.7,比肩o4-mini。而且,关闭思考模式成本直降600%。